Clustering Algorithms for Tag Clouds
Today I will talk about how to create tag clouds that display different levels of importance. At this I try to outline different approaches on how to cluster the tags by their importance significantly. I like to come up with a definition of what I am talking about first:
In this post
Today I will talk about how to create tag clouds that display different levels of importance. At this I try to outline different approaches on how to cluster the tags by their importance significantly. I like to come up with a definition of what I am talking about first:
“A tag cloud (or weighted list in visual design) is a visual depiction of content tags used on a website. Often, more frequently used tags are depicted in a larger font or otherwise emphasized, while the displayed order is generally alphabetical. Thus both finding a tag by alphabet and by popularity is possible. Selecting a single tag within a tag cloud will generally lead to a collection of items that are associated with that tag.” Wikipedia - Tag Cloud
When distinguishing the importance by font size it is common to choose a limited number of sizes. From the developer’s point of view that means that you have to accumulate tags into groups of equal importance to be able to give them the appropriate font size.
At first glance all tag clouds seem to be the same in the way of grouping. But there are several slightly different techniques to create this delicate second dimension of information when listing up tags.
To describe the different approaches I will use the following list of tags:
- ut1
- molestie2
- Lorem3
- urna4
- nisl5
- quod10
- Suspendisse11
- vitae12
- vestibulum15
- scelerisque16
- sit17
- Duis63
- Fusce64
- mauris65
- Quisque66
- toto94
- odio95
- Phasellus96
- tincidunt97
- non98
- libero100
- rutrum105
- Integer106
- Aliquam300
- ultrices301
As you can see, there are severale steps in their importance and there are two tags that have significantly more weight than the others.
Never daring to claim to know all clustering techniques I will outline my favourite three. Each of them has its pros and cons and is best for a different situation of tag weight.
Defined size of group
The easiest way of grouping the tags is to define, that each group has the same size. So if you have for example 30 tags and want to have 5 groups, you obviously get equal sized groups if you put 6 in each. The result is quite simple:
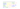
The advantage of this approach is it’s simplicity and that nevertheless you get quite a good look. Unfortunately you will lose any correlation between the tags, meaning a way more important tag can get the same size and therefore the same displayed importance. In our example that means that the two most important tags are together with the three following tags although there is a great difference in their importance. That is because their actual weight is not respected but only their actual position in the range of weights.Defined range of group
The second technique is a little bit more difficult, but it respects the relative weight of the tag. The approach is to divide the range between the weights of the most and the least important tag into equal sections. Then you put each tag into his range regarding to it’s actual weight:
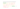
So this time we do not loose the correlation between the tags, also the algorithm is still quite simple. The main disadvantage of this technique is, that it suffers from outliers. If there is a tag that has way more importance than the other tags, there will be a huge gap between their weights, which will be separated into equal but empty sections anyway. So in our example you can correctly identify the two most important tags but because they have a great distance to the following tags two levels of importance are without any tag. In a way that is correct, but the tag cloud does not really look good.Clustering groups
The last technique I would like to present is clustering. Again, a definition:
”Clustering is the classification of objects into different groups, or more precisely, the partitioning of a data set into subsets (clusters), so that the data in each subset (ideally) share some common trait - often proximity according to some defined distance measure.“ Wikipedia - Cluster AnalysisIn my words I would say that by clustering the tags we can get a defined number of groups in which the difference between the importance of the tags is minimal.
Creating an algorithm for clustering weighted elements is not one of the easiest things to do, but fortunately there were a lot of smart brains out there that have already invented some. One of those algorithms is the K-means algorithm which I chose to implement in PHP. As you can see in the resulting tag cloud, the algorithm shows the two outliers correctly as the most important tags and arranges the other tags without skipping any level of importance: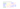
The disadvantage of this approach is that it can be very expensive at runtime according to the number of tags and groups you want to cluster.
To decide which approach to chose you need to consider the environment of the tag cloud.
The main advantage of the approaches using a defined size or range of the groups is of course their simplicity, which is good to reduce costs for implementation and at runtime.
A defined size of each group is useful if there is a difference in importance of the tags but no fluctuation in the number of tags that then have similar importance.
A defined range of each group is useful if there is difference and fluctuation in importance, but no outlier.
The clustering approach is the most flexible one that produces good results no matter which situation of tag weight is on hand. If movement of tag weight is seldom, the clustering can be calculated periodically by a cronjob. Otherwise you will have heavy resource usage for each user requesting the tag cloud. Anyway it is the most expensive approach regarding complexity of implementation.
You are welcome to comment and to download or make use of my code snippets.